How I Use AI to Work Across Microservices
TL;DR
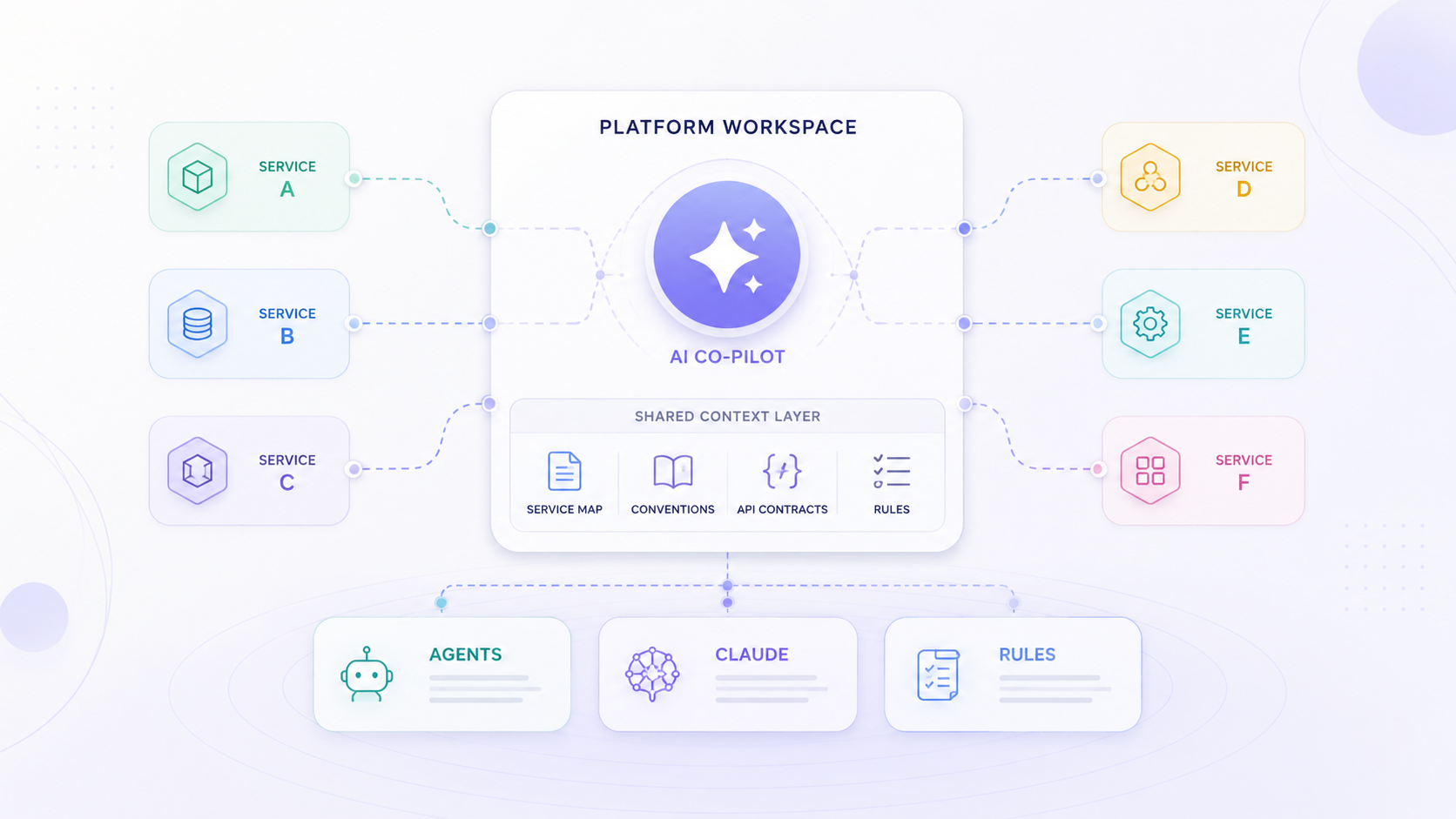
When working across multiple microservices, AI tools can easily lose context. I created a lightweight workspace layer above the services with shared docs, AI rules, service maps, and workflow conventions. The services stay as separate repositories, but the AI gets one place to understand how the system fits together.
The problem
Working with microservices usually means jumping between different repositories, terminals, routes, and responsibilities.
That is normal for developers, but it becomes more painful when using AI tools.
If I open only one service, the AI may not understand how that service connects with the rest of the system. If I open the full workspace without rules, the AI may look at too much code or suggest changes in places that should not be touched.
I found myself repeating the same context again and again:
- what each service does
- which service owns the data
- which service owns the business logic
- which routes or contracts connect them
- what should not be changed
- what was already changed somewhere else
That wastes time and tokens.
The solution
I created a lightweight parent workspace above the microservices.
Not a monorepo.
Not a replacement for Git.
Not a complex internal platform.
Just a simple workspace context layer.
Example structure:
platform-workspace/
├── .cursor/rules/
│ └── platform.mdc
├── docs/
│ ├── api-contracts/
│ ├── conventions.md
│ ├── feature-log.md
│ └── service-map.md
├── AGENTS.md
├── CLAUDE.md
├── README.md
└── workspace.code-workspace
Each microservice still stays as its own repository. The workspace only exists to give AI tools better context.
What I put inside
AGENTS.md contains general rules for AI agents:
- read the workspace docs first
- understand service ownership before editing
- do not change unrelated services
- explain the plan before modifying code
- verify assumptions in the real code
- avoid duplicating business logic across services
CLAUDE.md is specific to Claude and points to the shared instructions.
.cursor/rules/platform.mdc gives Cursor persistent rules inside the workspace.
docs/service-map.md explains the purpose of each service in a generic way:
- what it owns
- what it consumes
- what it should not do
- which other services it talks to
docs/conventions.md explains how cross-service work should happen.
Before making changes, the AI should identify:
- relevant services
- data owner
- business logic owner
- consumer service
- allowed folders
- expected files to change
- risks or assumptions
The important rule
Documentation helps with context, but the real code is still the source of truth.
The AI should use the docs to understand the system, but it should always verify the actual implementation before editing anything.
My workflow
For a small task inside one service, I open only that service.
For a cross-service feature, I open the parent workspace.
Then I give the AI clear boundaries:
Task:
Implement this feature across the relevant services.
Allowed folders:
- service-a/
- service-b/
Do not edit:
- unrelated-service-c/
- unrelated-service-d/
Before changing code:
Explain the implementation plan and list the files you expect to modify.
This keeps the AI useful without giving it unlimited freedom.
Why this helps
The main benefit is not automation. It is better context.
Instead of explaining the architecture from zero every time, the AI has a consistent place to start.
This helps with:
- fewer repeated explanations
- better cross-service understanding
- safer edits
- clearer implementation plans
- less token waste
- fewer accidental changes in unrelated services
Final thought
AI coding works better when the system context is structured.
For me, the useful pattern is:
central workspace context
+ service ownership docs
+ API contract notes
+ editor rules
+ real code verification
It is a simple setup, but it gives AI tools enough context to help across multiple repositories without turning the whole system into a monorepo.